> ## Documentation Index
> Fetch the complete documentation index at: https://allhandsai-add-helm-laminar-analytics-docs.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Critic
> Configure critic evaluation and iterative refinement in Agent Canvas.
The critic feature is experimental. Configuration options, scoring behavior,
and default models may change as the feature evolves.
The critic is an additional evaluation pass that reviews the agent's work and
predicts how likely the task is to succeed. In Agent Canvas, critic results can
appear in the conversation timeline as a success-likelihood score with detected
issue labels.
Use the critic when you want extra feedback for an OpenHands agent
conversation, or when you want the agent to automatically refine its work after
a low critic score.
The default OpenHands-hosted critic is currently free to use. For background
on the critic model and evaluation methodology, read
[SOTA on SWE-Bench Verified with Inference-Time Scaling and Critic Model](https://openhands.dev/blog/sota-on-swe-bench-verified-with-inference-time-scaling-and-critic-model)
and
[A Rubric-Supervised Critic from Sparse Real-World Outcomes](https://arxiv.org/abs/2603.03800).
The critic applies to OpenHands agent conversations. Agent Canvas can also
run third-party ACP agents, but those agents manage their own execution loop
and may not expose the same critic evaluation path.
## Prerequisites
Before enabling the critic:
1. Configure your active LLM in `Settings > LLM`.
2. Prefer the `OpenHands` LLM provider when you want the default hosted critic
path.
3. Start a new conversation after saving critic settings. Existing
conversations keep the settings they were created with.
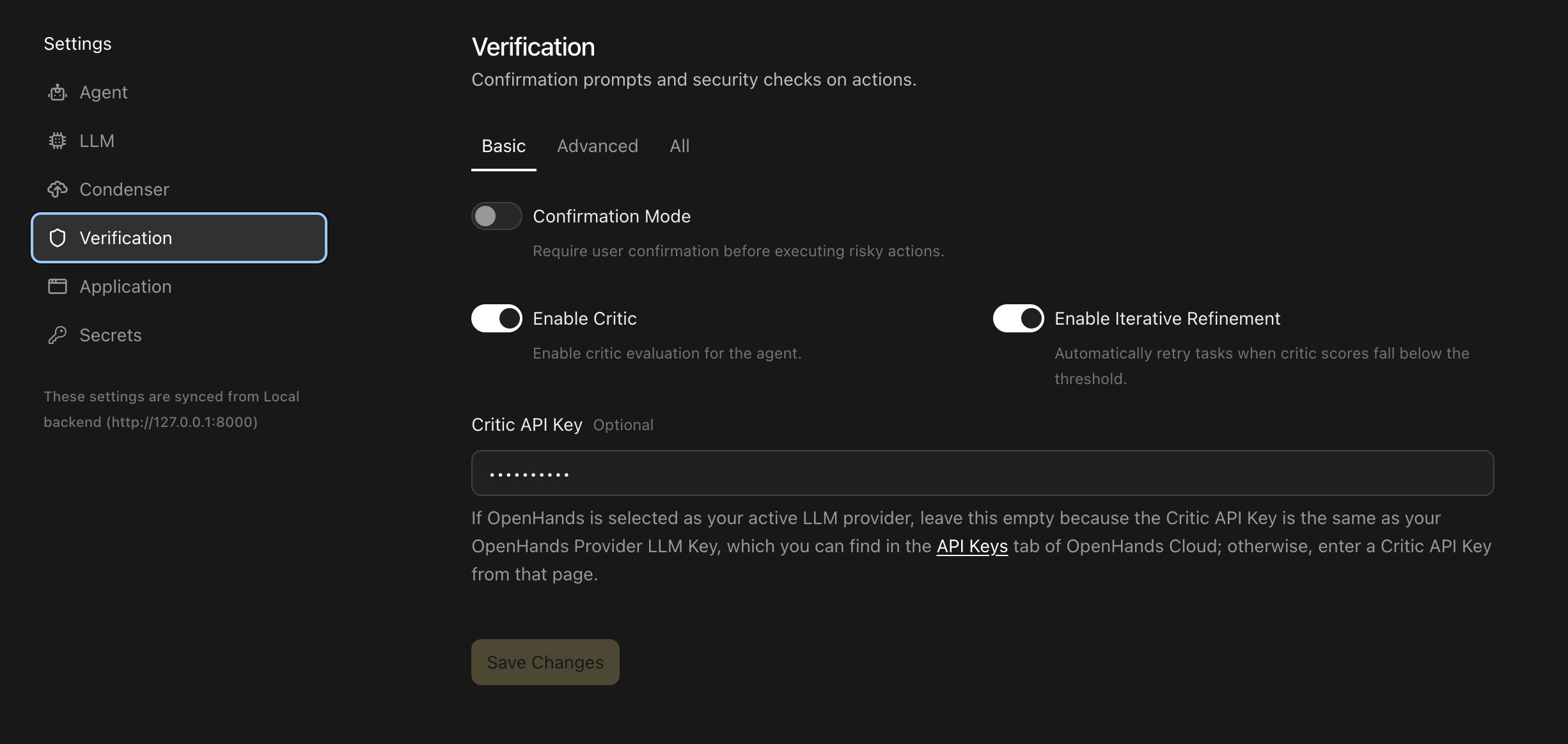
## Enable the Critic
1. Open `Settings > Verification`.
2. Toggle on `Enable Critic`.
3. Configure the `Critic API Key` field:
* If `OpenHands` is selected as your active LLM provider, leave this field
empty. The critic reuses the active provider's OpenHands Provider LLM Key.
* If you are not using the `OpenHands` LLM provider, paste an OpenHands
Provider LLM Key into `Critic API Key`, or provide the API key required by
your custom critic service.
4. Save the settings.
5. Start a new conversation.
 The Critic API Key and the OpenHands Provider LLM Key are the same credential
when you use the default OpenHands-hosted critic service. You can find that key
in the `API Keys` tab of [OpenHands Cloud](https://app.all-hands.dev/settings/api-keys).
The default hosted critic is free today; the key authenticates access to the
service.
A dedicated `Critic API Key` overrides the active LLM key for critic calls
only. Your main LLM configuration continues to use the key from
`Settings > LLM`.
## Enable Iterative Refinement
Iterative refinement lets the critic send the agent back to improve its work
when the predicted success score is too low.
1. Open `Settings > Verification`.
2. Toggle on `Enable Critic`.
3. Toggle on `Enable Iterative Refinement`.
4. Optionally switch the settings detail view to `Advanced` or `All`.
5. Adjust:
* `Critic Threshold` - the success score required to stop refining. The
default is `0.6`.
* `Max Refinement Iterations` - the maximum number of retry attempts. The
default is `3`.
6. Save the settings and start a new conversation.
When refinement is enabled, Agent Canvas will let the conversation continue
after a low critic score until the score passes the threshold or the maximum
iteration count is reached.
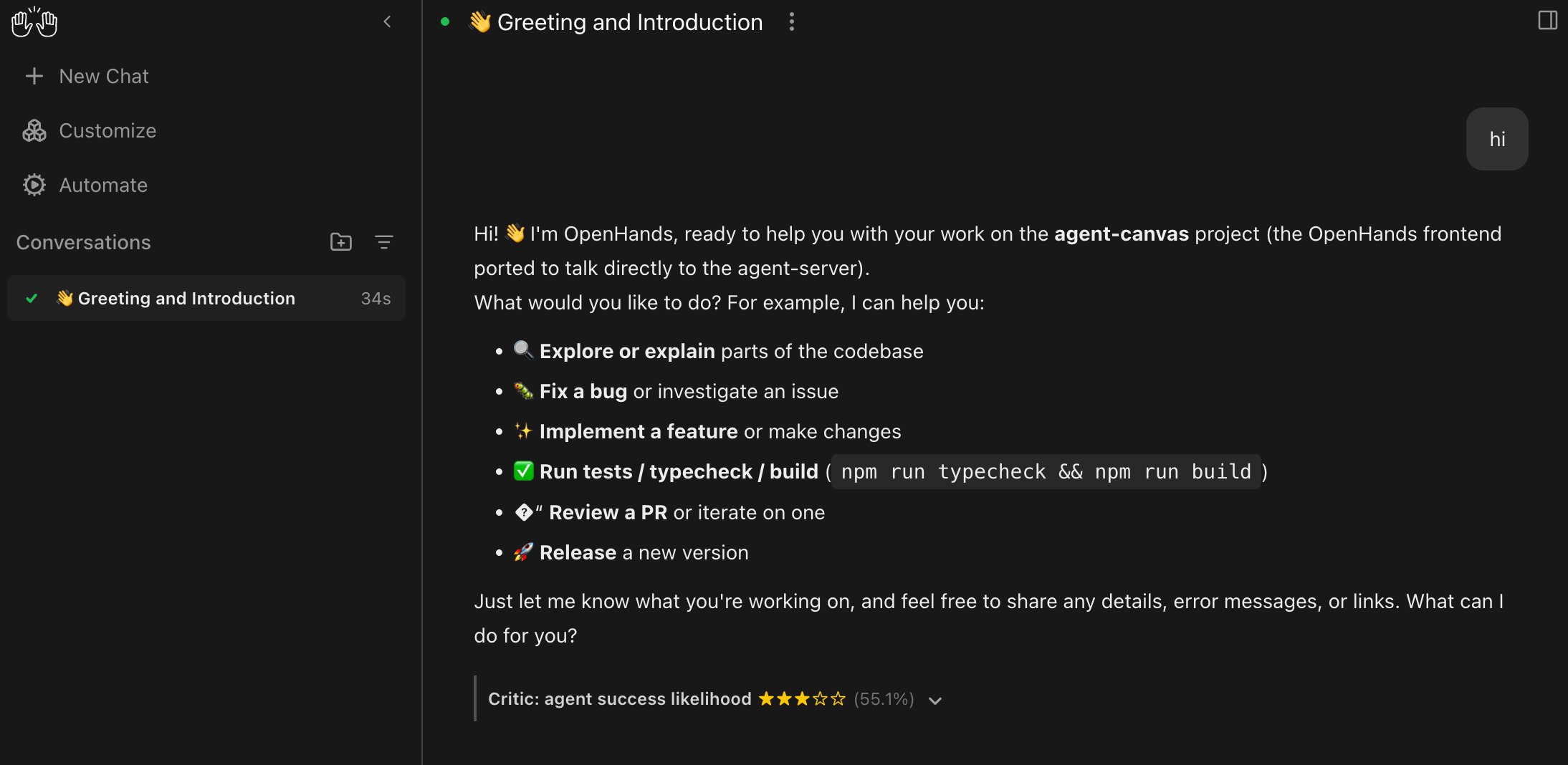
## View Critic Results
When the critic runs, Agent Canvas shows the result below the agent message or
finish action that was evaluated. The compact view shows the predicted success
likelihood score. You can expand the result to inspect detected issue
categories and probabilities, such as incomplete changes, missing validation,
infrastructure issues, or likely user follow-up patterns.
The Critic API Key and the OpenHands Provider LLM Key are the same credential
when you use the default OpenHands-hosted critic service. You can find that key
in the `API Keys` tab of [OpenHands Cloud](https://app.all-hands.dev/settings/api-keys).
The default hosted critic is free today; the key authenticates access to the
service.
A dedicated `Critic API Key` overrides the active LLM key for critic calls
only. Your main LLM configuration continues to use the key from
`Settings > LLM`.
## Enable Iterative Refinement
Iterative refinement lets the critic send the agent back to improve its work
when the predicted success score is too low.
1. Open `Settings > Verification`.
2. Toggle on `Enable Critic`.
3. Toggle on `Enable Iterative Refinement`.
4. Optionally switch the settings detail view to `Advanced` or `All`.
5. Adjust:
* `Critic Threshold` - the success score required to stop refining. The
default is `0.6`.
* `Max Refinement Iterations` - the maximum number of retry attempts. The
default is `3`.
6. Save the settings and start a new conversation.
When refinement is enabled, Agent Canvas will let the conversation continue
after a low critic score until the score passes the threshold or the maximum
iteration count is reached.
## View Critic Results
When the critic runs, Agent Canvas shows the result below the agent message or
finish action that was evaluated. The compact view shows the predicted success
likelihood score. You can expand the result to inspect detected issue
categories and probabilities, such as incomplete changes, missing validation,
infrastructure issues, or likely user follow-up patterns.
 ## Troubleshooting
### Critic Results Do Not Appear
* Confirm `Enable Critic` is on in `Settings > Verification`.
* Start a new conversation after saving the setting.
* Use the OpenHands agent path. Third-party ACP agents may not expose critic
results.
* Wait until the agent sends a message or finishes a task. With the default
`finish_and_message` mode, the critic does not run after every tool call.
### Authentication Errors
If the critic request fails with an API key or authentication error:
* If `OpenHands` is the active LLM provider, leave `Critic API Key` empty and
confirm the active LLM profile has a saved OpenHands Provider LLM Key.
* If another LLM provider is active, enter an OpenHands Provider LLM Key in
`Critic API Key`.
### Conversations Become Slow
* Keep `Critic Mode` set to `finish_and_message` unless you need per-action
feedback.
* Disable `Enable Iterative Refinement` if you only want passive critic scores.
* Lower `Max Refinement Iterations` if repeated refinement loops are too costly.
## Related Guides
* [Customize and Settings](/openhands/usage/agent-canvas/customize-and-settings)
* [LLM Profiles and Model Configuration](/openhands/usage/agent-canvas/llm-profiles)
* [OpenHands LLMs](/openhands/usage/llms/openhands-llms)
* [SDK Critic Guide](/sdk/guides/critic)
* [Critic Model Blog Post](https://openhands.dev/blog/sota-on-swe-bench-verified-with-inference-time-scaling-and-critic-model)
* [Critic Research Paper](https://arxiv.org/abs/2603.03800)
## Troubleshooting
### Critic Results Do Not Appear
* Confirm `Enable Critic` is on in `Settings > Verification`.
* Start a new conversation after saving the setting.
* Use the OpenHands agent path. Third-party ACP agents may not expose critic
results.
* Wait until the agent sends a message or finishes a task. With the default
`finish_and_message` mode, the critic does not run after every tool call.
### Authentication Errors
If the critic request fails with an API key or authentication error:
* If `OpenHands` is the active LLM provider, leave `Critic API Key` empty and
confirm the active LLM profile has a saved OpenHands Provider LLM Key.
* If another LLM provider is active, enter an OpenHands Provider LLM Key in
`Critic API Key`.
### Conversations Become Slow
* Keep `Critic Mode` set to `finish_and_message` unless you need per-action
feedback.
* Disable `Enable Iterative Refinement` if you only want passive critic scores.
* Lower `Max Refinement Iterations` if repeated refinement loops are too costly.
## Related Guides
* [Customize and Settings](/openhands/usage/agent-canvas/customize-and-settings)
* [LLM Profiles and Model Configuration](/openhands/usage/agent-canvas/llm-profiles)
* [OpenHands LLMs](/openhands/usage/llms/openhands-llms)
* [SDK Critic Guide](/sdk/guides/critic)
* [Critic Model Blog Post](https://openhands.dev/blog/sota-on-swe-bench-verified-with-inference-time-scaling-and-critic-model)
* [Critic Research Paper](https://arxiv.org/abs/2603.03800)